5월 16일 AWS Summit Seoul 2024 컨퍼런스에 다녀왔습니다.
AWS Summit Seoul은 국내 최대의 IT 클라우드 행사이며, 각 주요 기업에서 AWS를 활용하여 어떤 변화와 혁신을 일으켰고 그에 대한 내용을 공유하는 자리라고 볼 수 있겠습니다.
또한, 다양한 기업 부스 체험 및 구경을 통해 각 기업들이 가진 클라우드 전략, 미래 방향성, 기술 체험 등을 구경할 수 있는 자리이기도 합니다.

Day 1의 주제는 산업별 비즈니스 트렌드이며 각 IT 산업에서 AWS를 활용하여 어떤 변화와 혁신을 만들어냈는지가 주된 내용이었습니다.
Day 2의 주제는 생성형 AI 기반 기술 혁신이었습니다. 주제들을 보니, 생성형 AI를 통해 어떠한 혁신을 이루었는지에 대한 내용들이 주 내용이었습니다.
저는 Day 1에만 참여하였습니다.
강연은 주로 다음과 2가지 중 하나로 진행되었습니다.
1. AWS의 기술을 활용하여 변화를 만들어낸 경험에 대한 강연
- AWS 솔루션즈 아키텍트분이 강연에서 사용된 AWS의 서비스 및 기술 설명
- 이후 발표자분이 AWS를 활용하여 어떤 변화와 혁신을 만들어냈는지에 대한 과정, 결과 등에 대한 내용
2. IT 트렌드와 기술 등에 대한 혁신 방법, 미래 변화, 전략, 사례 공유 등을 통한 인사이트를 넓힐 수 있도록 도와주는 강연

기조연설 (09:30 ~ 10:40)
함기호 (대표이사)
- AWS의 발전과정(lambda 등)과 기계학습에 대한 내용
- Project Ceiba 진행을 통해 AI처리 기술을 향상중
- 생성형 AI는 더 진화할 것이다. 그에 맞춰서 학습 모델과 비즈니스를 혁신해야 함
- AI 기술의 발전이 인간에게 위험하지 않도록 책임있는 AI를 만들어 위험을 최소화 하고 생성형 AI의 잠재력은 극대화 할 수 있어야 한다.
송재하 (배민 CTO)
- 2019년 CQRS 방식 + MSA 아키텍처로 변경
- 커머스 시스템에서 중요한 것은 결제와 정산영역이며 AWS를 통해 최초로 결제정산시스템을 클라우드에 옮길 수 있었다.
- 엔데믹 이후 Cloud FinOps 사용하여 AWS 비용을 절감할 수 있었다.
정석근(SK Telecom)
SKT의 AI 전략에 대한 설명한다.
- AI 반도체, AI 인프라 등을 통해 글로벌하게 나아가려고 한다.
- 통신사의 축적된 데이터를 통해 Telco LLM을 개발하고 있다. 올 하반기부터 사용할 예정
- 글로벌 통신사 사용률 1위 클라우드인 AWS와의 협업중
이와 같이 여러 기업에서는 생성형 AI와 AWS의 기술력을 사용하여 기업 비즈니스를 혁신하고 더 좋은 서비스 개발에 힘쓰고 있음을 듣게 되었습니다.
Amazon OpenSearch Service로 열어가는 미래 (11:10 ~ 11:50)
분야 : AI/ML

우리가 평소에 구현하거나 사용하는 검색 방식은 Keyword 기반 검색입니다.
그러나, 이는 검색된 정보가 여러 태그를 가지고 있거나 키워드 주제와 상관없이 검색된 정보에 들어있으면 내가 원하지 않는 내용도 노출되어 불편함을 느끼게 됩니다.
이를 개선하기 위해 AWS의 Amazon OpenSearch Service를 사용하여, 벡터 기반 검색을 진행하였습니다.
벡터 검색이란, 동일한 단어라도 다른 숫자의 배열로 표현하여 고차원의 공간에 저장 유사한 데이터 포인트를 찾는 기술입니다.
- 눈이라는 단어는 하늘에서 내리는 눈 우리 신체부위의 눈이 있다. 둘은 같은 단어이지만 벡터 공간 내에서는 서로 떨어져 있다.
- 지구 온난화, 기후 위기는 다른 단어이지만 벡터 공간 내에서 가까이 있을 것이다.
사용 이유
- AOSS의 기능인 벡터 엔진 검색(위치 벡터와 가까운 사람들을 검색할 수 있음)을 하기 위함
- keyword검색 대신 semantic 검색을 통해 후보자 프로필의 맥락(키워드 검색이 아닌 유사한 경험을 지닌 지원자를 찾기)을 파악하기 위함
- AOSS 가 다른 OpenSource들의 기능 + 큰 차원의 벡터 처리 연산이 가능
- Amazon SageMaker(대규모 ML모델을 빌드, 훈련, 배포 하는 서비스)를 통해 검색 정확도 최대화
벡터화된 표현을 활용하여 AWS의 AOSS는 680억개의 데이터를 저장하고 80억개의 데이터를 스캔해서 99%이상의 짭퉁을 잡아낼 수 있었다.
Summary
Amazon OpenSearch Service를 활용하여 채용 검색 혁신이 가능하였습니다. 키워드 기반이 아닌 유사한 내용을 지닌 정보만을 검색할 수 있으며, 이를 통해 400 만명의 등록된 인재중 채용 담당자가 적절한 인재를 빠르고 쉽게 찾을 수 있게 되었음을 설명 해주셨습니다.
RDBMS에서 NoSQL 로의 전환 (13:10 ~ 13:50)
분야 : DevOps, Cloud

Amazon DynamoDB
- 대규모 성능, 안전하고 탄력적, 암호화, 가용성, 서버리스(프로비저닝 또는 용량 관리 없고 요청당 지불 청구), 손쉬운 AWS 통합 가능
- DynamoDB Streams를 활용한 이벤트 소싱시 DynamoDB는 Stream을 보장해준다.
- OLTP 등의 워크로드 처리에 적합
- 급격한 트래픽에 대해서는 처리가 어렵다. 비동기 처리가 가능하다면 SQS 사용과 함께 처리하자.
Amazon Simple Queue Service
- 간편한 오버헤드, 안정성, 보안, 효율적인 확장 가능
- 무제한 처리량, FIFO 대기열로 전달
※ 서버리스를 사용하는 이유
- 인프라 프로비저닝과 관리 불필요, 자동 스케일링, 사용한만큼만 지불, 고가용성과 보안
※ 문제발생
- 스파이크 트래픽 & 비용 비효율 (큰 트래픽만 한번씩 처리하고 있다가 Job이 끝남 중간에 계속 리소스가 남음)
- 부하 전파 (outbound로 내보내는 요청은 별개로 처리하고 싶어하였다.)
- Operation 호환성 (RDMBS → NoSQL로 이전하면 모두 구현할 수 있는가?)
- 마이그레이션시 다운 타임 발생 (DB를 변경해야 함, rdmbs → dynamodb 다운타임 없이 가능한가?)
※ 해결방법
- 온디맨드 모드와 프리워밍, 프로비저닝 모드와 오토스케일링으로 처리 가능
- dynamoDB는 사용한 만큼만 나오므로 큰 트래픽에 대한 비용만 해결하면 됨
- 독립적인 테이블에 대한 설계를 통해 해결
- 새로운 테이블을 설계하였고, dynamoDB 트랜잭션을 활용하여 원자적으로 구현
- 채팅방 클릭 → 모두 읽음 → 읽은만큼 cnt를 빼줌 → 트랜잭션 WriteItem에서 처리 함으로써 정합성 해결
- dynamoDB는 낙관적 잠금을 지원함 (동시에 데이터 접근이 일어나면 예외 발생)
- 병렬 스캔 아이디어 차용 (아이디어 해쉬화 → 워크로드에 뿌려줌)
- 다운타임은 발생하였음. 그러나 최대한 빨리 해결할 수 있었음
※ Live Migration 전략 수립
개발 → 새로운 스키마 정의 → Lambda 작성(예전에 생성된 스키마를 새로운 테이블의 스키마로 람다 표현식 작성) → 예전 테이블에 Write → lambda → 새로운 테이블에 Write
※ Amazon SQS 사용 방법
- 트래픽을 보관하는 버퍼로 사용
- 완전 관리형
- 스파이크 트래픽을 크게 주어도 큐는 버틸 수 있다.
- 큐 뒤의 컨슈머가 빨리 처리해서 딜레이가 생기지 않게 관리 해주어야 한다.
- 적절한 키 디자인
※ Consumer 구성법
최초 : Amazon SQS → AWS lambda → Application 순서 구성, 그러나 이 방법은 컨트롤 하기 어렵고 좋지 않다고 느낌
변경 : Application(별도의 스레드를 두고) → poll 요청 → Amazon SQS → 수신 후 삭제 방식으로 변경
※ 웹훅 처리 방법
같은 레코드에 대해 동시에 Write가 발생하면 Conflict가 발생함
Retry를 시도하면 되지만, 이는 인스턴스에 추가적인 부가 트래픽이 발생, Redis 분산 락으로 구현하려 했으나 SQS의 선입선출 방법을 통해 분산 락 구현 하지 않고 이를 해결함
Summary
Amazon DynamoDB, Amazon Simple Queue Service 를 활용하여 급격한 트래픽에 대한 처리 과정을 알려주셨으며, 개발자로서의 CS(Computer Science)에 대한 고민이 정말 많이 묻어있던 세션이었습니다.
안정적인 대규모 처리를 위한 성능 향상을 위한 RDBMS를 무조건 4xLarge로 Scale Up 하면 될 줄 알았으나, 여러 문제들이 발생하였고 이를 해결하기 위해 NoSQL로 전환하게 되었습니다.
결과적으로, DynamoDB + Lambda + Amazon SQS를 활용하여 수평확장을 하였고 실시간 Migration 전략을 실행하였으며 AWS 기술력과 CS를 활용한 문제 해결에 대해 복합적으로 정말 많이 고민했던 내용이 담겨있었습니다.
디지털 자산 플랫폼으로의 첫 걸음, 토큰증권 시스템 on AWS (14:20 ~ 14:50)
분야 : 금융, 핀테크, 법

Summary
디지털 자산 시장이 커지고 있는 만큼 관련 가상자산법도 시행됩니다. 이제 여러 은행, 증권사도 블록체인을 활용한 금융자산을 디지털 토큰 형태로 발행하게 될 것이며, 이러한 토큰증권을 통해 자산을 사고 파는 새로운 마케팅 전략이 나타날 것이라고 하였습니다. 이는 곧 금융 혁신을 가져올 것이라고 합니다.
토큰증권 아키텍처 구현은 기존 증권 은행이 가지고 있는 Legacy System의 변동을 최소화 하기 위한 Middle Layer + 블록체인 구축 시스템과 같이 구현하는 방향에 대해 설명해주셨습니다.
하이퍼커넥트의 AWS Graviton 이전을 위한 거대한 도전과 여정 (15:20 ~ 16:00)
분야 : DevOps, Cloud

AWS에서 AWS 워크로드를 최적의 상태로 만들 수 있도록 만드는 맞춤형 실리콘을 만들어 가는중
AWS Nitro System, AWS Graviton, AWS Inferentia and AWS Trainium
AMD 64 기반 AWS WorkLoad에서 Graviton으로 마이그레이션 한 이유는 Intel에 비해 최대 20% 이상의 감소된 비용이기 때문이다.
※ 배포 전략
Github enterprise → spinnaker pipeline (jenkins,Helm) → k8s 렌더링 → Rollout canary, blue-green 등의 배포 전략을 사용중 입니다.
※ Migration Strategy 수립
- 서비스 ListUp 마이그레이션에 필요한 kubectl, cur 분석
- 사용중인 서비스 분석
- 외부 벤더사로부터 제품을 제공 받을 경우
- ARM64를 지원하지 않을 경우 에뮬레이터 사용이 가능하나 퍼포먼스가 떨어짐 벤더사에 요청하는게 좋
- 지원할 경우 쉽게 이관 가능
- Open-Source 제품일경우
- ARM64를 지원하지 않을 경우 직접 소스코드 수정
- 지원할 경우 그대로 사용
- 하이퍼커넥트 자체 기술일 경우
- 외부 벤더사로부터 제품을 제공 받을 경우
- 계산식을 만들어 Graviton의 사용률을 정한다.
- 난이도 임팩트 서비스 영향도 고려해서 우선순위를 정한다 .
- Non-business Critical 서비스 부터 마이그레이션
- High vCPU Usage 사용률이 높은 서비스 마이그레이션
- No HA / Mission Critical 등의 서비스는 조심스럽게 진행
- Data Processing (Batch) 임팩트가 떨어지고 레거시 코드들에 대해서는 마지막에 진행
도커 명령어를 통해 arm64만 지원하는지 amd64만 지원하는지 cli 창에서 도커 이미지 확인 가능함
※ 프로그래밍 언어별 Migration 난이도
- Go Rust - static linked binary를 생성하기 때문에 쉬움
- Java,Scala,Kotlin - JNI 기술 때문에 종종 까다로움
- Python - arm64 아키텍처를 지원하지 않는 라이브러리가 많아서 어려운 편
※ 마치며
오래된 코드는 유지보수가 어려움 코드를 변경하지 않고 마이그레이션 할 수 없을까?
- QEMU(InitContainer 사용), Box64 등을 사용하면 공수를 크게 들이지 않고 완료 가능하다.
graviton은 발전속도도 빠르고 비용 절감도 있기 때문에 사용을 추천한다.
대신, 마이그레이션에 시간이 걸리니 꼼꼼하게 점검 후 천천히 마이그레이션 진행해보자
관련 내용이 작성된 블로그[1]은 하단에 추가하였습니다.
Summary
AMD 64 기반 AWS WorkLoad에서 비용을 최대 20% 절감 가능한 ARM 64 기반 AWS Graviton으로 마이그레이션 하는 방법에 대한 내용을 들을 수 있었습니다.
마이그레이션 전략을 수립하고, 우리의 서비스를 분석하고 ARM 64 아키텍처를 지원하지 않을 때는 어떤 방법들을 통해 호환성을 맞추는지 등을 들을 수 있었습니다.
케이뱅크의 클라우드 도입 여정: 빅데이터, 채널, MSA, AI/ML (17:20 ~ 18:00)
분야 : DevOps, Cloud
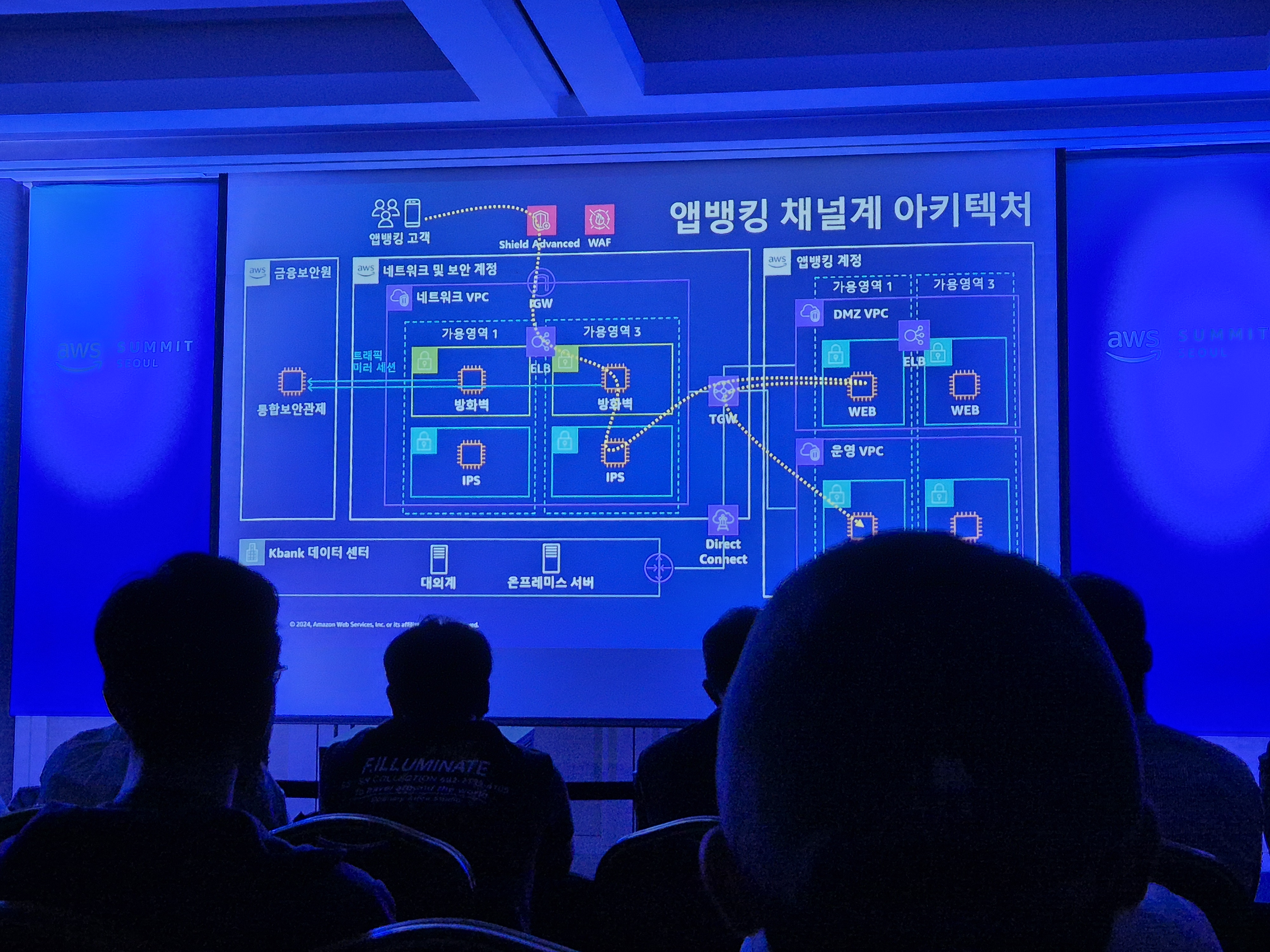
케이뱅크는 비즈니스적인 전략과 확산을 위해 클라우드를 사용합니다.
케이뱅크는 채널계 확장, MSA 도입, 데이터 플랫폼 전환을 위해 클라우드를 도입하였습니다.
※ 클라우드 도입 여정
- 채널계 확장
- 순식간에 몰리는 트래픽을 감당하기 어렵다. 고객 유입을 분산하자
- IDC #1, IDC #2, AWS 고객부하를 Active, Passive가 아닌 Active, Active, Active로 분산
- 5 : 3 : 2 트래픽으로 분산하였으며, 트래픽이 몰리면 AWS에서 오토스케일링 함
- 클라우드는 리눅스를 사용하므로 유닉스 → 리눅스로 전환 필요
- 이를 통해 하이브리드 클라우드로 채널계를 구성하였음
- 순식간에 몰리는 트래픽을 감당하기 어렵다. 고객 유입을 분산하자
- MSA 도입
- 금융에서 MSA 적용이 어려운 이유
- 이미 모놀리식에 맞게 만든 조직에 맞게 프로세스를 바꿔나가야함(역콘웨이 법칙)
- 망분리 환경
- 전환하기 위해서 막대한 비용이 필요
- 금융에서 MSA를 할 사람이 없다.
- 그럼에도 MSA를 하는 이유는 더 많은 고객, 마케팅, 상품, 서비스를 출시하기 위해 MSA들을 장점을 수용하려고 한다.
- 적용 과정
- 위험도 낮은 시스템 우선 → 코어뱅킹 서비스 → 코어뱅킹 핵심 계정계(여수신)
- MSA를 활용한 서비스 제공
- request → ELB에 요청 → EKS 클러스터(각 pod)에 트래픽 전달
- 금융에서 MSA 적용이 어려운 이유
- 데이터 플랫폼 구성을 위해 S3, EMR, MSK, Lambda, SageMaker, bigdata 등을 조합하였습니다.
※ On-premise -> AWS 환경으로 개선
On-premise Hadoop Cluster는 확장성에 단점이 있음 이를 해결하기 위해 AWS를 사용함 (거버넌스 환경 구축에 힘들었음)
on-premise 환경일 때는 탄력적인 사용이 불가하였으나 AWS를 통해 자원을 유연하게 필요할 때만 사용할 수 있게 되었다.
전자금융감독규정에 의해 정기적으로 클라우드에 백업/분산 하고 있다.
Summary
AWS의 Auto-Scaling을 활용해 채널계를 확장할 수 있었고, MSA 도입이 매우 어려운 환경임에도 MSA의 장점을 수용하기 위해 천천히 적용되는 과정을 설명해주셨습니다.
또한 고객 데이터 플랫폼 구성을 위해 AWS의 다양한 데이터 처리 서비스들을 구축하였습니다.
고객 중심 서비스를 만들기 위해 클라우드화 하는 여정을 계속 진행하겠다는 내용을 들을 수 있었습니다.
AWS Summit Seoul 2024에서 다양한 세션들을 통해 인사이트를 더 넓힐 수 있는 기회가 되어 좋은 경험이 되었습니다.
[1] https://hyperconnect.github.io/2023/07/25/migrate-half-of-workload-in-a-year.html
'회고록 > 후기' 카테고리의 다른 글
| 2023 오픈소스 아카데미 컨트리뷰션 후기 Challenges & Masters (0) | 2023.11.13 |
|---|---|
| 수료하고 쓰는 SW 마에스트로 13기 합격 후기 (4) | 2023.01.03 |

